What is (Deep) Reinforcement Learning?
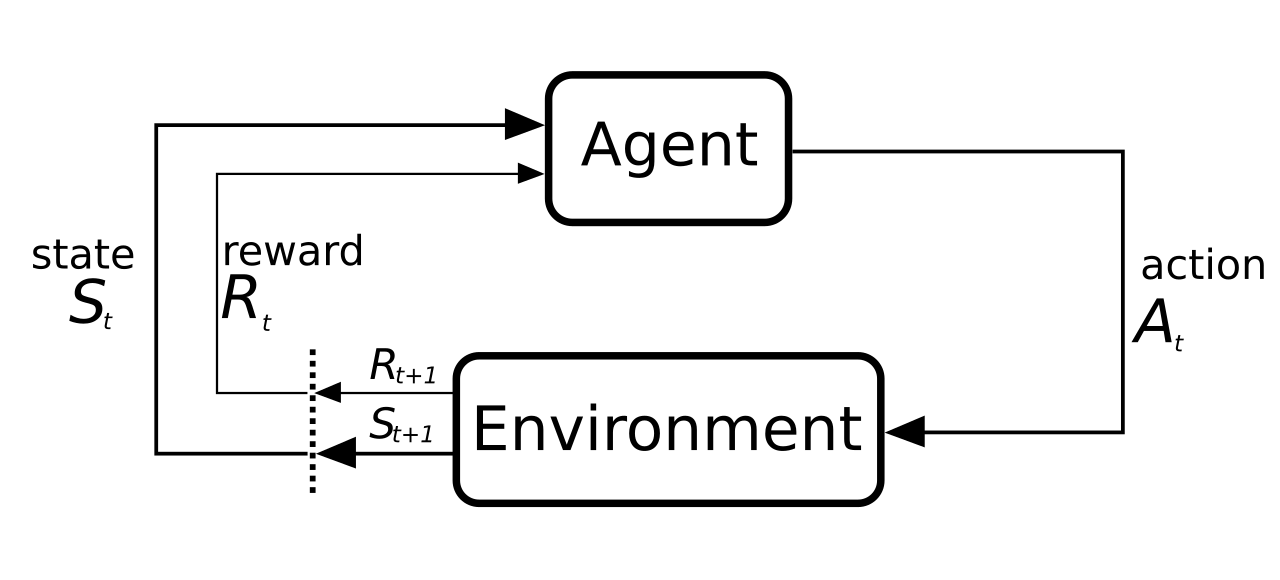
In Reinforcement Learning (RL) an agent learns by trial and error. The agent knows the current state of the environment and takes an action according to a policy. The environment transitions into a new state and responds with the observation of the new state and a scalar reward. The reward represents the usefulness of the action. The goal is to maximize the cumulative reward from taking actions in an environment. In RL it is important to find the right tradeoff between exploration of new territories and exploitation of learned behaviour.
Source: commons.wikimedia.org
{kind=link}
The agent tries to learn an optimal policy through interaction with the environment. The policy maps actions to states. Another important function is the value function, which calculates the expected future rewards when following the policy. This is used to compare different policies and find the best one. RL uses adaptive algorithms to learn the needed functions.
Additional Information: Reinforcement Learning - wikipedia.org
Deep RL combines deep learning with RL. Neural Networks (NN) are used instead of adaptive algorithms. The policy and value functions are learned by a NN. In some algorithms, like Actor-Critic, several NNs are used to learn the policy and value functions independently. The largest benefit of Deep RL is that it allows much larger state dimensions than conventional RL.
Additional Information: Deep Reinforcement Learning - Wikipedia, Actor Critics - The AI Summer
Hexapod RL
The Hexapod RL is distributed across two devices. On the PC runs the deep learning part and a Hexapod environment which remote controls the real Hexapod. On the Hexapod runs a server which provides a continuous sensor stream and accepts movements of the servo motors.
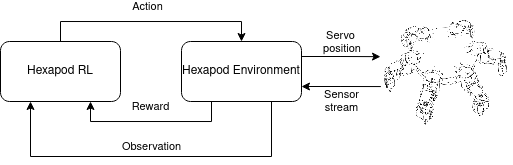
Action
The action space of the Hexapod consists of 18 values between -1.0 and 1.0. These represents the negative or positive movement of the 18 servos of the hexapod. The value is interpreted as the percentage of the step size.
Coxa1 |
Femur1 |
Tibia1 |
... |
Coxa6 |
Femur6 |
Tibia6 |
Environment
The environment for this application is the Hexapod Environment class. The agent can perform a step with a given action. The Hexapod environment calculates the new servo positions from the action considering the limitations of the leg movements e.g., do not stab yourself. The new servo positions are sent to the Hexapod. The observation and reward are calculated from the continuous sensor stream after the real Hexapod executed the servo movement.
Observation
The observation is an array containing the following values:
- Servo positions (calculated)
- Accelerometer (x,y,z)
- Gyroscope (x,y,z)
- Orientation (roll, pitch, yaw)
- Height (above ground)
This array of 28 entries is the current state of the environment.
Reward
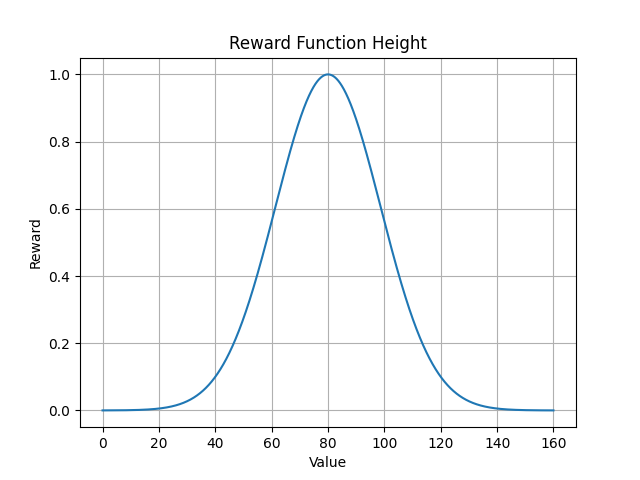
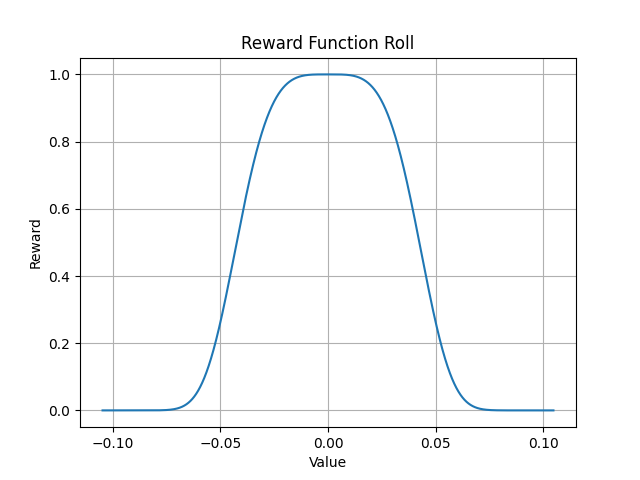
The Hexapod Environment uses parametrizable exponential functions to calculate the reward from the current state. To learn standing up the reward considers height, roll and pitch. Each of the three parameters has its own exponential function. The result of every reward function is multiplied to a single scalar. Further a reward scaling for bad behaviour is used. This is a value between 0.0 and 1.0 multiplied to the reward. Bad behaviours are trying to move a servo beyond its limit or the need for limiting the leg movement to not stab itself. The two images show an example reward function for the height in millimetres and the roll in radians.
Agent
The agent used for the Hexapod is a Twin Delayed Deep Deterministic policy gradient algorithm (TD3) (Fujimoto et al., 2018). TD3 shows excellent performance in the control tasks with continuous action space included in MuJoCo and OpenAI Gym. For this project, the original PyTorch implementation of the paper presenting TD3 was used. TD3 is an improved actor-critic algorithm. It uses two actor and two critic networks for better stability and faster learning. Each of those networks is a simple feed forward NN. A replay buffer is used to store past experiences. After every action performed, a mini batch of past experiences is used to update the networks.

Source: commons.wikimedia.org
{kind=link}
At the beginning completely random steps are performed to gain some experience in the environment. Afterwards the agent uses the current observation of the environment to decide the next action. Exploration noise is added at every action, so that the agent tries different actions for the same observation.
Source + Additional Information:
- sfujim TD3 - github.com
- Addressing Function Approximation Error in Actor-Critic Methods - arvix.org
- TD3: Learning To Run With AI - towardsdatascience.com
How does it look in the simulation?
The video of the simulation shows 3000 random steps and 12000 training steps. The agent tries to get the hexapod to stand up but is not yet fully successful. In some scenes can be seen that the Hexapod stabs itself with the legs. This happens in the simulation, because the MuJoCo environment interprets the angle as force. Therefore, a limitation of the angle to prevent this behaviour does not work.
How does it look with the real Hexapod?
The video shows a short training sequence of the Hexapod. At first it performs some random steps. Afterwards it uses observed behaviour and tries to stand up. The result in the video is not ideal, but it clearly shows that the agent is learning.