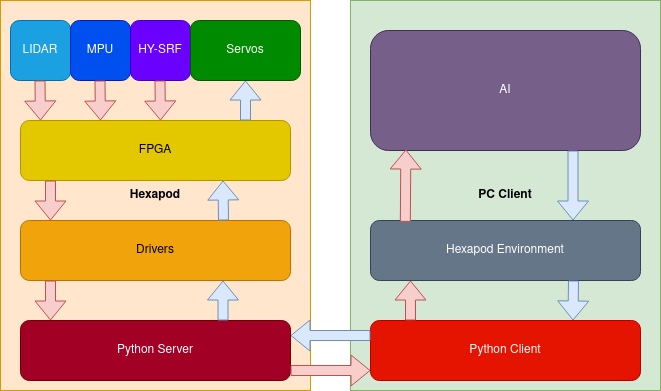
The goal of this project is to let the famous HSD/ESD hexapod learn how to walk via reinforcement learning. This sounds like a rather simple task, but comes with many challenges. At first, it was necessary to port the existing Robotics FPGA implementation from Lattice Architecture to Intel FPGA architecture. Additionally, parts of the initial implementation had to be omitted (like the interface to a PS2 controller), since they were not needed anymore. Secondly, on the System-on-Chip an operating system became mandatory, in order to use the advantages of linux, python and easy communication implementations coming with it. Therefore, we built a custom linux distribution with yocto.
When training something with reinforcement learning, feedback has to be provided. To get this feedback from the hexapod, we decided to use an accelerometer, a gyroscope, a distance sensor and a lidar. Those sensors are read by linux drivers and their values are sent to a client (where the reinforcement learning model lives) via python and ethernet. The python environment processes those values (for example it calculates the roll, pitch and yaw coordinates from accelerometer and gyroscope and therefore knows how the hexapod is currently oriented in the room) and the reinforcement learning model generates new normalized values for the 18 servos of the hexapod. These values are based on a mix of learning experience and exploration. Exploration is necessary to overcome local extrema in the learning curve. Custom 3D-printed parts made sure the sensors stay at their desired location and make the hexapod look even more futuristic.
We started to train our model with help of the physics simulation framework Mujoco. Mujoco's documentation was still under construction, so examples were not only minimal, but sometimes even missing for certain features. Strange errors and missing community forums made it difficult to create a functional model, which behaves like reality.